
優秀な外交官のように交渉の場を整え、
熟練した編集者のように表現を洗練させ、
そして深夜でも休まない献身的なアシスタントのように常に待機。
これが、近年驚異的なスピードで進化するAI翻訳の姿です。企業の海外展開を強力に後押しする頼もしい存在として、ビジネスの世界地図を塗り替えつつあります。とりわけ2024年7月に実装されたDeepL社の「次世代言語モデル」は言語翻訳、文章校正の特化型大規模言語モデル(LLM)技術を搭載。ついに人間の翻訳品質に肉薄するレベルを実現しました。しかし、その進化の一方で、誤訳のリスクは決して影を潜めていません。
「こんなに高性能なのに、なぜ誤訳が起きるの?」
多くの方がそう思うのも無理はありません。実はAI翻訳の”得意・不得意”はまだまだ言語や分野によって偏りがあり、医療や法律など誤訳が致命的となりやすい領域では十分な注意が必要です。
本記事では、今後企業が押さえておくべき「AI翻訳のリスクと対策」を包括的に解説します。初心者でも理解しやすいように、誤訳が起こるメカニズムや具体的な企業事例、そして最新技術動向に基づいた対策まで解説。翻訳・多言語コンテンツの品質管理を考えている企業にとって、今後のビジネス戦略に役立つ情報となれば幸いです。
AI翻訳の現状と誤訳のメカニズム
AI翻訳がもう人間を超えたのか、どうかについてはさまざまな意見があります。実際は、言語ペアや分野によって精度にムラがあるのが現状です。誤訳が生まれる背景を知っておくことで、より賢くリスク管理を行うことができるでしょう。

大規模言語モデル(LLM)の躍進と現状
2024年11月に開催された国際翻訳評価「WMT24」では、OpenAIのGPT-4やAnthropic社のClaude 3.5など、多数のLLMを搭載した翻訳システムが出場しました。
注目を集めたのは、Unbabel社が開発した機械翻訳に特化した多言語大規模言語モデル(LLMのUnbabel-Tower70Bが自動評価で全言語ペアでトップとなり、Claude 3.5は人間評価で9言語ペアで最高評価を獲得しました。OpenAIのo1、GoogleのGemini-1.5 Pro、AnthropicのClaude 3.5といったモデルが従来の翻訳システムを性能面で上回り、機械翻訳の新時代を告げる結果となりました。
また、2025年3月現在はGemini 2.0、Claude 3.7 Sonnetとバージョンアップされています。
Googleの公式発表によると、Gemini 2.0はマルチモーダルな能力において大きく前進し、特に出力関連の機能強化です。従来のテキスト生成に留まらず、独自の画像生成技術と制御可能な多言語音声合成(text-to-speech)機能を新たに搭載しています。これらの追加機能によって、ユーザーとのコミュニケーション方法が多様化するとされています。
ただし、同時に指摘されたのが「まだ人間の翻訳を凌駕したわけではない」という点。
研究者も「自動評価指標だけでは翻訳品質を完全に評価できない」と注意を促しており、人間による評価が依然として重要であることを強調しています。多くの言語ペアでは依然として人間の翻訳がトップ評価を維持しており、「LLM時代が来たからといってAI翻訳にすべて任せられるわけではない」ということを再認識させられる大会となりました。
【出典】The 9th Conference on Machine Translation in Miam
【出典】 Introducing Gemini 2.0: our new AI model for the agentic era
誤訳はなぜ起きる?3つの代表的原因
AI翻訳は驚くほど進化したものの、まだ完璧とは言えません。特に以下のような状況で誤訳が発生しやすく、その仕組みを理解しておくことがリスク回避の第一歩となります。
1.専門用語や固有名詞の取り扱いの難しさ
医療、法律、科学技術、研究書など一般のテキストとは異なる専門領域になると、言語モデルが誤訳を起こしやすくなります。
disorder の例:現代医療の流れを反映していない機械翻訳
2013年に公開されたDSM-5(精神疾患の診断・統計マニュアル第5版)の日本語翻訳ガイドラインについて書かれた文書では、精神医学における重要な用語の翻訳に関する課題と方針を示しています。
その方針の一つとして、「障害」という言葉が患者や家族に大きな心理的影響を与えるということで、特定の領域(児童青年期の疾患と不安症関連)では”disorder”を「障害」ではなく「症」に変更することになりました。
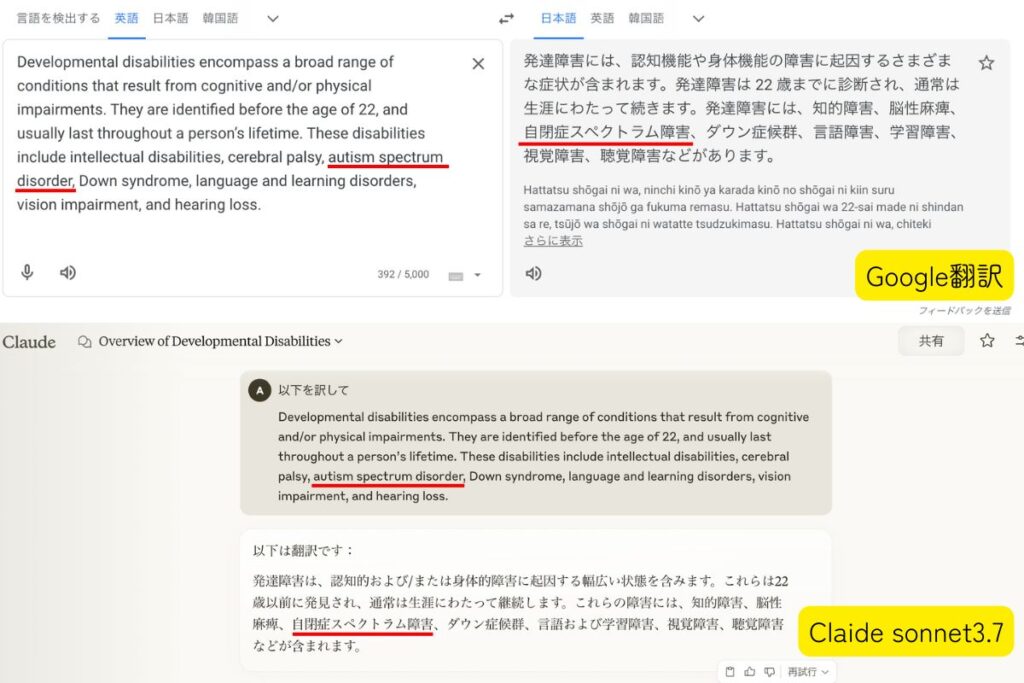
今では広く知られている「自閉症スペクトラム症(ASD: Autism Spectrum Disorder)」(※1)もそのひとつです。
しかし、Google翻訳やDeepLをはじめ、言語能力に長けているとされるClaude sonnet3.7でも「自閉症スペクトラム障害」と訳されています。
※1自閉症スペクトラム症:発達障害の一種で、主に社会的コミュニケーション・対人関係の困難さと、限定された興味や反復的な行動パターンを特徴とする神経発達症です。
※2025年3月21日現在の結果
こうした日本医療の流れをくめない機械翻訳は、公開から10年以上経過しているのにもかかわらず、正確な訳はできません。
似たような例では、「Tic Disorders」は「チック障害」と訳されてしまうため、そのまま使用してしまうと「時代と逆行した表現だ」と批判されてしまうかもしれません。
addicotionの例:正確な意味や文脈を理解していない機械翻訳
“addiction”という単語は日本語だと「中毒」と訳されがちですが、専門的な文脈だと「嗜癖(しへき)」または「依存症」と訳すことが一般的です。それぞれの言葉の違いは以下の通りです。
嗜癖(しへき):特定の行動や習慣への強い心理的執着を指し、行動への渇望や衝動が特徴。心理的・行動的な側面が強調され、買い物嗜癖やギャンブル嗜癖のように物質を伴わない依存にもよく使われる。
依存症(いそんしょう):物質や行動への強い渇望と制御不能な状態を表す医学的・臨床的な診断名。心理的依存と身体的依存の両方を包括し、有害な結果にもかかわらず行動を継続する点が特徴的。
中毒(ちゅうどく):主に物質の摂取による生理的・化学的な影響を強調する言葉で、急性と慢性の両方の状態を指し、英語では”Intoxication”を使うことが一般的。急性中毒は一時的な過剰摂取による状態、慢性中毒は物質への長期的な依存状態を表すことが多い。
そのため、以下のaddictionを使用した例文では、対訳が適しているといえます。
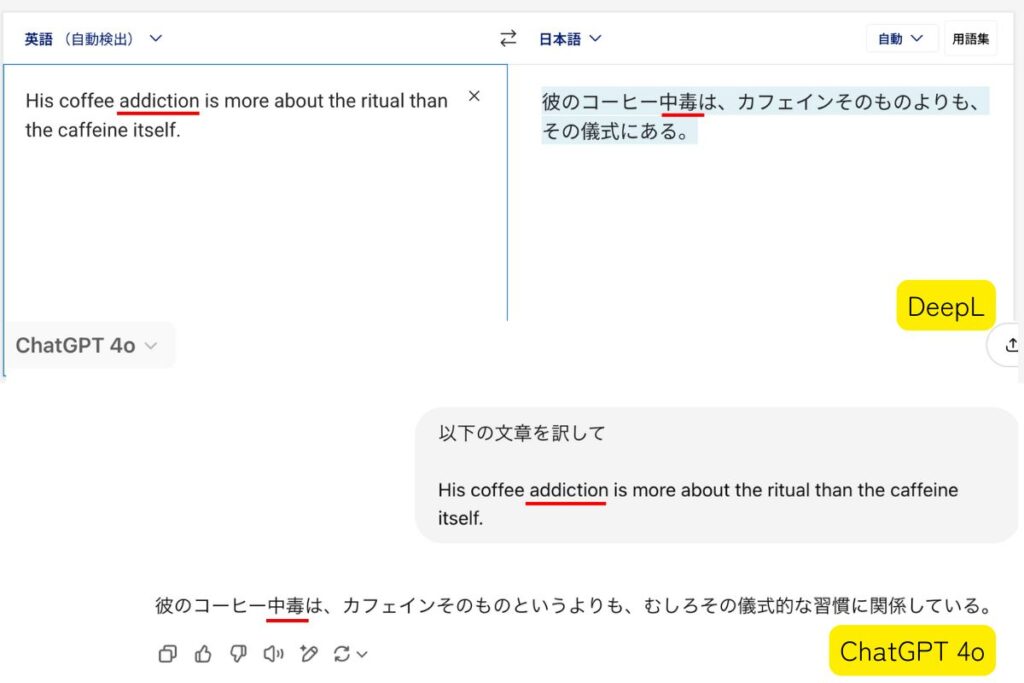
例文)His coffee addiction is more about the ritual than the caffeine itself.
対訳1)彼のコーヒー嗜好は、カフェイン自体よりも習慣化された行動パターンに起因している。
対訳2)彼のコーヒーへの(嗜癖)依存傾向は、カフェイン摂取の薬理学的効果よりも、反復的な行動様式としての側面が強い。
しかしながら、機械翻訳では安直に以下のように訳されてしまいます。
※2025年3月21日現在の結果
物質摂取が原因であることが低いと後半に説明されているのにもかかわらず、「中毒」という言葉が使われています。
このような例から、AIは言葉の正式な定義もしくは文脈を理解しないで翻訳してしまうケースがあることがわかります。
2.文脈依存の誤解
慣用句や比喩表現などを直訳してしまうと、本来の意味を大きく損ねてしまいます。文脈を正しく理解できるかどうかはAI翻訳の大きな課題です。
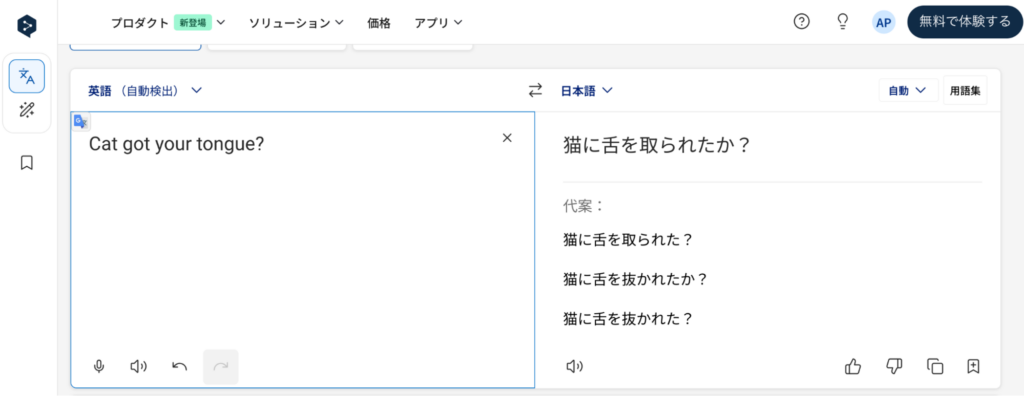
例えば、「Cat got your tongue?」は英語の慣用句で、「猫に舌を取られた?」という直訳になりますが、実際の意味は「どうして黙っているの?」「何か言うことはないの?」という表現です。
他にも「to hit the books」のような慣用句を含む文は誤訳されやすい例です。この表現は「一生懸命勉強する」という意味ですが、AIは「本を叩く」と直訳してしまう傾向があります。
3.言語ペア間の非対称性
英語―スペイン語などデータ量が豊富な主要言語ペアでは極めて高い精度を示す一方、学習データが少ないマイナー言語同士(低リソース言語)では誤訳が生じやすい傾向があります。
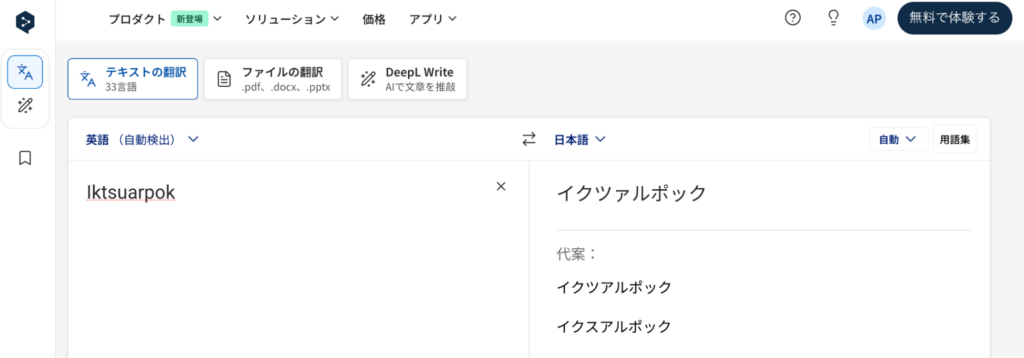
DeepLでは、イヌイット語(イヌクティトゥット語)で「外へ出て見て誰かが来るんじゃないかと期待する気持ち」を指す「Iktsuarpok」は正しく翻訳できませんでした。
「言語」だけではないAI利用のリスク
「誤訳」に関して、先ほど3つの代表的な例をお伝えしましたが、AIが生成する「もっともらしい嘘をつく」ハルシネーションのリスクも存在します。
翻訳を含むAIサービス全般における重大なリスクと言えるでしょう。例えば「1897年の米国と南極大陸の戦争」のような架空の事実についても、AIは詳細な情報を創作してしまいます。
これでどのようなことが起きるかというと、外国語の内容について調べた時には、誤訳リスクに加えて、ハルシネーションを起こすリスクという2重のリスクが生じるということです。
日本語など母国語であれば意味を理解し、明らかな間違いに気づくことができますが他言語ではそれができないのです。
さらに、ファクトチェックをしようと思っても内容が専門的であればあるほど、最新の翻訳ツールを使ったところでまったく歯が立ちません。
ビジネスにおけるAI翻訳のリスク
AI翻訳で生じる誤訳は、ただの”言葉の間違い”にとどまりません。医療や法律などの高リスク分野であれば生命や法的権利に関わる重大問題に発展しますし、マーケティングやブランディング領域では売上や企業信用に直結するおそれがあります。
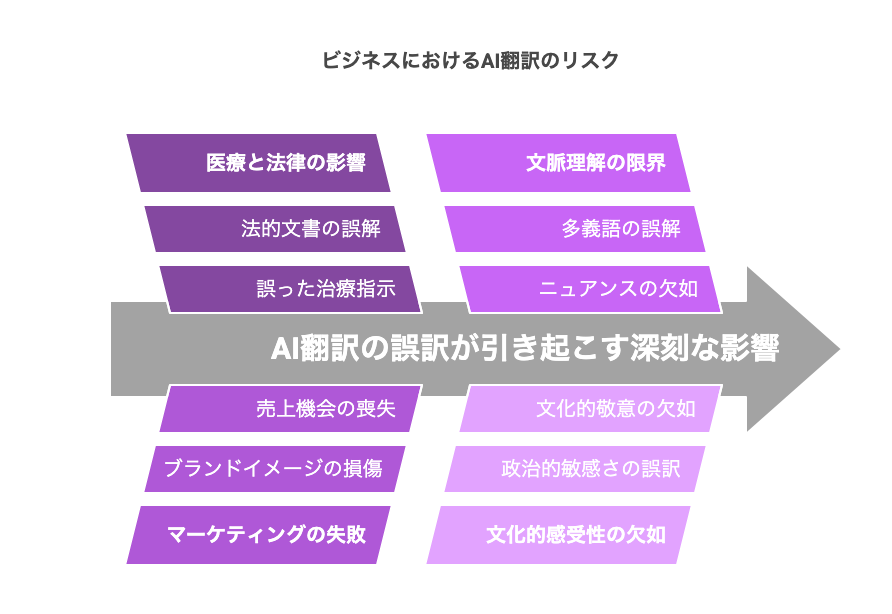
ハイリスク分野:医療・法律における影響
医療分野では患者の安全が最優先事項であり、翻訳ミスは治療方針や薬の用法を誤らせるリスクがあります。例えば、服薬指示の微妙なニュアンスの違いが患者の体調に致命的な影響を与える可能性も否定できません。法律分野でも、移民・亡命申請書類に機械翻訳をそのまま使った結果、申請者の不利益につながる事例が報告されています。
マーケティング領域:ブランドイメージへのダメージ
ECサイトや商品紹介ページ、SNS投稿など、消費者が直接目にするコンテンツに誤訳があると、「この企業、大丈夫かな?」と不信感を与えてしまいます。
例えばAmazonで商品を選んでいる時に、ふとした商品説明文に違和感を感じたり、ところどころ他言語が入っていて違和感を持ったことはないでしょうか。
サンパウロに本社を置くデジタルマーケティング企業のSherlock Communicationsが実施したラテンアメリカの消費者を対象にした調査では、企業サイトで翻訳ミスを見つけた場合、77%がその企業の商品購入をやめる可能性があると回答しています。
また、その地域において約460億ドル規模の売上機会を失いかねないという報告もあります。
事例:誤訳が招いた深刻なダメージ
「誤訳がビジネスに与える影響」を具体的に理解するため、実際の事例を見てみましょう。これらの例を通じて、翻訳ミスが時に企業に深刻な損失をもたらすことがわかります。企業の成功と失敗を分ける一線は、時として正確な翻訳にかかっているのです。
Microsoft Copilot「養子縁組キット」誤訳事件
2024年9月、マイクロソフト公式サイトに「Microsoft Copilot 養子縁組キット」という奇妙な表記が登場しました。これは「Microsoft Copilot Adoption Kit」の誤訳で、英語の「Adoption」が持つ「導入」ではなく「養子縁組」の意味が選択されたことによるものです。
発生した問題
- AI翻訳が「Adoption」の文脈を適切に把握できず誤った意味を選択
- AI技術を推進するマイクロソフト自身のサイトで翻訳ミスが発生という皮肉
- 「AIと血縁関係を結べる時代」と冗談めかしたコメントがSNSで拡散
- 「AI技術の品質が疑われる」という懸念の声も
Microsoftの対応
- この誤訳は発見後、正しい「Microsoft Co誤訳の発見後、「Microsoft Copilot 導入キット」に表記を修正
- 公式サイトの翻訳チェック体制の見直し
この事例は、AIによる機械翻訳が進化している一方で、文脈理解や多義語の適切な意味選択にはまだ課題が残っていることを如実に示しています。
重要なコミュニケーションでは人間による最終チェックが不可欠であり、AIツールは強力な助けになりうるものの、その出力を盲信せず適切に監視・活用することの重要性を教えています。特に専門用語や複数の意味を持つ単語を扱う際は細心の注意が必要です。皮肉にもAIチャットサービスを提供する企業自身のサイトでこうした失敗が起きたことは、現時点でのAI技術の限界を象徴的に表す事例となりました。
NHK:AI自動翻訳字幕の誤訳によりサービス終了
2025年2月、NHKは国際報道のライブ配信中、重大な翻訳ミスを発見しました。尖閣諸島に関するニュースで、AI自動翻訳が生成した中国語字幕に、日本の「尖閣諸島」が中国側の主張する「釣魚島」という呼称で表示されていたのです。
発生した問題と対応
- 政治的に敏感な誤訳をNHK職員が発見
- 「NHKのサービスとして相応しくない」との即日判断
- Google翻訳APIを使用していた多言語字幕サービスを完全停止
NHK広報部の説明
- 「自動翻訳は完全ではない可能性がある」との注意書きを付けて運用していた
- 国営放送としての信頼性を損なう恐れがあると判断
- 過去の配信記録調査で直近4日間に複数の同様の誤訳を確認
この事例は、政治的文脈を理解せずに機械的に訳語を当てはめるAI翻訳の限界と、報道機関がリアルタイム翻訳を使用する際のリスク管理の重要性を浮き彫りにしました。
Meta(Facebook):国王即位投稿の誤訳で謝罪
2024年7月、米Meta社はFacebook上の自動翻訳機能による重大なミスで公式謝罪を発表しました。マレーシアの公共放送局RTMがマレー語で投稿した第17代国王即位の祝賀メッセージが、Facebookの自動翻訳システムによって英語では「お悔やみの言葉」として誤って表示されたのです。
発生した問題
- RTMの国王即位祝賀メッセージがFacebookの自動翻訳で「弔意表明」に
- 慶事に対して不適切な弔意を表明したかのような誤解が広がる
- 王室関係者やマレーシア国民の間に混乱と不快感を生む
Meta社の対応
- 「技術的エラーが原因」と説明
- 「マレーシア王室を深く敬意しており、関係各所に迷惑をかけたことを心よりお詫びする」との声明を発表
- 翻訳機能の不具合を速やかに修正
RTM側も「英語翻訳が誤っていただけ」と釈明しました。この事例は、SNS上の自動翻訳ミスが公共機関の信用や文化的敬意に及ぼす影響と、プラットフォーム企業の危機管理対応の重要性を浮き彫りにしています。
【出典】Microsoft Copilot 養子縁組キット」MS公式サイトに爆誕 「Adoption」の誤訳か
【出典】AI自動翻訳翻訳機能による多言語字幕サービスの終了について
【出典】 Meta apologises over translation error by Facebook relating to Malaysian King’s installation
AI翻訳技術と最新動向
こうしたリスクがある一方で、AI翻訳の進歩はますます加速しています。特に2024年は、大手企業やスタートアップ各社が新たなLLMを導入し、主要言語ペア(翻訳において頻繁に使用される言語の組み合わせ)の翻訳品質を高めています。
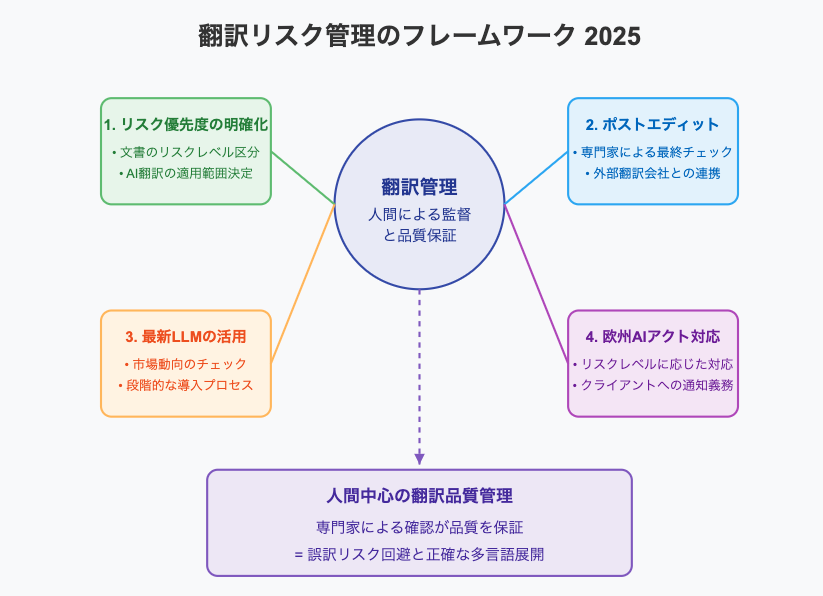
人間参加型ポストエディットの進化
2025年2月に発表された、効率的な機械翻訳に関する研究では、AI翻訳と人間の編集(ポストエディット)作業を組み合わせた新しい翻訳手法が紹介されました。
主なポイントは次の通りです。
- 人間とAIの協働モデル: 大規模言語モデル(LLM)と人間の編集者(アノテーター)を組み合わせた「Human-in-the-Loop」(人間参加型)の翻訳プロセスを提案しています。
- 主な技術的革新について:
- 強化翻訳合成: 複数の機械翻訳出力を組み合わせてより良い翻訳案を生成
- アシスト注釈分析: LLMが翻訳品質を自動評価
- 疑似ラベリング: 予備的なフィルターとして機能し、⼈間による翻訳の量を削減
- 翻訳推奨システム: 特定の状況で最適な翻訳を提案
- どんな効果があるの?:
- 翻訳品質が平均4.33%向上
- 人間の編集者の作業負担を軽減
- 最適な翻訳モデルの選択精度が向上
- システム:
- 翻訳者用インターフェース: エラーの分類、翻訳の選択、編集作業を行う
- 管理者用ダッシュボード: 翻訳品質の監視、データ分析、自動ラベル付けの制御
この研究は、AIと人間の強みを組み合わせることで、翻訳の質を保ちながら効率を高める方法を示しています。システム全体が翻訳品質の向上を目的としており、間接的に誤訳リスクの軽減に貢献するものと考えられます。
簡単に言えば、「AIが下訳と初期チェックを行い、人間はより重要な判断や仕上げに集中できる」というシステムです。従来の「AI翻訳→人間が全部チェック」より効率的に、でも品質は保ったまま翻訳作業を進められる方法論というわけです。
一見すると、効率化のメリットしか感じられないかもしれませんが、2025年現在も誤訳を繰り返す生成AIの品質が4.33%向上したとしても、人の手と目で確認する部分の減少は微細かもしれません。
システムでエラーに対する分類を行うということは、裏を返せばそれだけ翻訳にエラーが発生するということです。
マイナー言語への対応強化
Google、Cohereをはじめとする大手企業が、あまり知られていない言語(低リソース言語)の翻訳精度を上げる取り組みを進めています。
2025年2月、GoogleはSMOL(Set of Maximal Overall Leverage)という新しいデータセットを公開しました。
概要:
- 専門の翻訳者が作成
- 世界の115の希少言語に対応
- 合計610万の翻訳サンプルを収録
この取り組みの意義は大きく、これまでAI翻訳の恩恵を受けられなかった少数言語を話す人々もデジタル世界に平等に参加できるようになります。
ただし、こうした言語は元々の学習データが少ないため、英語や日本語のような主要言語と同レベルの翻訳精度をすぐに達成するのは難しい現状です。それでも2025年以降も継続的な改良が予定されており、徐々に精度が向上すると期待されています。
【出典】SMOL: Professionally translated parallel data for 115 under-represented languages
誤訳ゼロを目指して:企業のリスク管理と対策
ではAI翻訳を利用する場合、どう誤訳リスクを最小限に抑えればよいのでしょうか。企業が取り組むべきポイントを4つにまとめました。
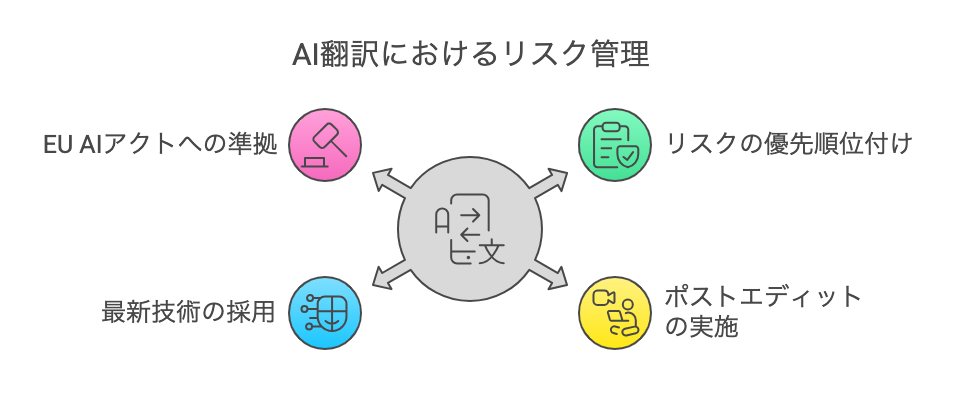
1. 翻訳リスクの優先度を明確化する
企業の中で取り扱う文書には、契約書や医療関連資料、マーケティング素材、SNS投稿など、さまざまな種類があります。
- 医療・法律・契約書など高リスク分野 → 原則として専門家のチェックやポストエディットが必須
- SNSや社内コミュニケーションなど低リスク分野 → ある程度スピードやコストを優先
といったように、それぞれの文書のリスクレベルを区分し、それに応じてAI翻訳の利用範囲を決めることが大切です。
医療・法律・契約書など高リスク分野では、人命に関わったり、企業であれば甚大な損失につながるためコストをかけてでも誤りのない翻訳を行わなければなりません。
無条件にすべてをAI翻訳に任せるのではなく、明確な基準を設けてから導入しましょう。
2. ポストエディットと専門家連携の活用

たとえ翻訳精度が高まったとはいえ、マイナー言語や専門用語が散りばめられた文章などはまだまだ誤訳が生じやすい領域です。
イギリスの翻訳会社Wolfestone社の2025年1月のLinkedInブログでは、AI 翻訳の改善と共に「人間主導または 100%人間による翻訳ワークフローもお勧めします。人間の翻訳者は、機械では必ずしも再現できないレベルの文化的理解をもたらします」と言及しています。
AI翻訳を仮に使うとしても専門知識のある翻訳者や編集者が最終チェックを行う仕組みは必須でしょう。
これまでとりあげた事例でもお分かりいただけると思いますが、AI任せの自動翻訳は企業に良い結果をもたらすどころか、信用を失墜させる事態になりました。
自社内に十分なリソースがない場合は、外部の翻訳会社や編集プロダクションを活用するのも有効です。経験豊富なプロの目は、AI翻訳の見落としを拾い上げる”安全弁”として働いてくれます。
3. 最新LLMを取り入れる柔軟性と慎重さのバランス
AI翻訳を取り巻く技術は、今後も加速度的に進化していくでしょう。新しいバージョンのLLMが公開されるたびに、翻訳精度や対応言語の幅、文体制御機能などが向上するという触れ込みが盛んになります。
しかし、こうした最新技術を事業に取り入れる際には慎重さも必要です。
バランスの取れたアプローチ
- 定期的な市場動向のチェック: 最新モデルの性能や対応言語の情報を収集
- 段階的な導入プロセス: 非重要文書での試験運用から始め、実績を確認してから適用範囲を拡大
- 検証期間の確保: 新モデル導入前に十分なテストと品質評価を実施
- リスク評価: 業種や文書の重要度に応じた慎重な判断基準の設定
- 品質管理体制の構築: 継続的なモニタリングと評価の仕組みづくり
特に重要な事業文書や顧客向けコンテンツには、検証済みの安定したシステムを使い続けることが賢明な選択となる場合も多いのです。マイナー言語対応や専門性の高い分野では特に注意が必要で、2025年以降も継続的な検証と品質管理がカギとなるでしょう。
4.欧州AIアクト(EU AI Act)への対応
2025年に本格施行される欧州AIアクト(EU AI Act)は、欧州連合(EU)が制定した世界初の包括的なAI規制法です。このAI規制法は、翻訳業界にも大きな影響を与えようとしています。この法規制ではAIシステムを4つのカテゴリーに分類し、リスクレベルに応じた規制を適用します。
- 容認できないリスク
- 高リスク
- 限定的リスク
- 最小リスク
特に翻訳会社は、使用するAIツールの詳細なレビューが必要となり、高リスクと判断される場面では厳格な対応が求められます。具体的には文書化、リスク管理、技術的コンプライアンス、そしてデータ処理慣行などにおいて厳しい基準を満たす必要があります。
また重要なのは、翻訳業務でもしAIを使用する場合、クライアントへの明示的な通知が義務付けられることです。これにより、翻訳プロセスの透明性が高まる一方で、翻訳会社側の管理負担は増加すると予想されています。
欧州市場で活動する翻訳関連企業は、この新しい規制枠組みへの準備が急務となっています。
【出典】EU AI規則の概要
【出典】Must-Know Translation & Localisation Trends for 2025
AI翻訳を鵜呑みにしない姿勢をしっかりともつ
AI翻訳は、2024年末以降のLLM導入によって格段の進化を遂げました。とはいえ、低リソース言語の誤訳や医療・法律の専門性の高さなど、リスク要因は依然として数多く存在しています。誤訳が企業にもたらす影響は、単なる言い間違いを超え、患者の安全や企業ブランド、法的なトラブルにまで波及し得るほど深刻です。
企業が2025年以降のグローバル市場で勝ち抜くためには、AI翻訳を正しく使いこなしつつ、人間の専門性を組み合わせたリスク管理が必要不可欠です。具体的には、
- 文書のリスクレベルに応じた翻訳方針の策定
- ポストエディットと専門家チェックの仕組みづくり
- 最新LLMやマイナー言語対応の継続的なウォッチと柔軟な導入
といった取り組みが効果的と言えます。
いわば「AI+人間」のハイブリッドな翻訳体制こそが、誤訳リスクを最小化しつつスピード感ある多言語展開を実現する最強のソリューションです。まるでハイブリッド車が燃費とパワーを両立するように、AIの効率性と人間の創造力・専門性を並行して活用することが、これからの企業翻訳戦略の要となるでしょう。
翻訳精度が日々向上する一方で、誤訳が企業に与えるリスクは決して小さくありません。だからこそ企業の担当者には、「誤訳をただの他人事と考えない」視点と、「AI翻訳をもっと賢く使っていく」工夫の両方が求められます。今こそ、AI翻訳の可能性と限界を正しく理解し、堅実かつ柔軟なリスクマネジメントを備えることで、多言語マーケットの新しい扉を堂々と開いていきましょう。